The Lazy Data Scientist's Fantasy Football Rankings
Blending fantasy football expert rankings with rank aggregation methods
I originally wrote this post on Towards Data Science before moving it here.
This is an article about creating fantasy football rankings. I claim (without proof… yet) that these rankings will be more reliable than most you’ll find on the internet. And we won’t need to do any fancy modeling to predict player performance. In fact, we won’t use player performance data at all!
How can we possibly create accurate rankings without player performance data? We’re going to let other people do most of the hard work for us!
It’s 2019 and fantasy football has taken the world by storm. From hardcore fans to people who don’t know a fumble from a frisbee, everyone is playing fantasy football. Even my mom joined a league this year. (Well, she didn’t really, but it wouldn’t be too surprising.)
The game is so popular that “fantasy football expert” has become a viable career path. Lots of people get paid to rank players and provide advice to virtual team managers every week. It may sound like a cushy job, but those experts really know their stuff and they put in a ton of effort to stay up to date on the ever-changing NFL landscape.
These experts are going to provide the data we’ll use to create our player rankings. We’ll simply take the rankings published by a bunch of individual experts and blend them together into one single ranking. The accuracy of any individual expert tends to be a bit erratic from week to week (and year to year), but the group should be quite accurate on average.
Why do I think this is the best way to produce data-driven player rankings? Why not use past player performance data to predict future performance? I’m not arrogant—I don’t think I could build a very good model to predict player performance. Most experts are good at their jobs. Their combination of data analysis, scouting, and football knowledge will result in better player projections than any model I come up with. If you can’t beat ’em, give up and take their results.
You might be thinking: doesn’t something like this already exist? Yes, there are websites (such as FantasyPros) that produce “consensus” rankings by combining rankings from individual experts… but I think I can do it better.
Methodology: Rank Aggregation
FantasyPros uses a really simple method of combining rankings from individual experts. For each player, they just take that player’s average rank in all of the experts’ lists. For example, if six experts rank Saquon Barkley as the #1 player, three rank him as the #2 player, and one ranks him as the #3 player, Barkley gets an average rank of 1.5.
There’s an entire field of study called rank aggregation devoted to finding the best ways to combine ranked lists from individual base rankers into a consensus, or aggregate, ranking. I think many rank aggregation methods are better suited to our ranking task than the FantasyPros method.
I won’t go into detail on any rank aggregation methods here (maybe that’ll be a future post), but I’ll briefly discuss instant runoff as an example. You might be familiar with instant runoff if you’ve heard of ranked choice voting. In ranked choice voting, voters rank candidates in order of preference rather than voting for a single candidate. To determine the winner we have to aggregate the voters’ rankings, and instant runoff is a common way of doing that. Candidates receiving the fewest first-place votes are repeatedly eliminated and have their votes reassigned until one candidate has the majority of the first-place votes. The application of instant runoff to elections is obvious, but there’s nothing stopping us from applying the same algorithm to fantasy football rankings.
Most rank aggregation methods focus on is pairwise preferences, and I think that’s important for our fantasy football objective. For example, if most experts prefer Player A to Player B, then A should be ranked higher than B in the aggregate list. The FantasyPros average method does not achieve this — if a single expert ranks Player A really low, that might drag the average down far enough to put A below B in the aggregate list. It’s not hard to find a real example in the FantasyPros draft rankings:
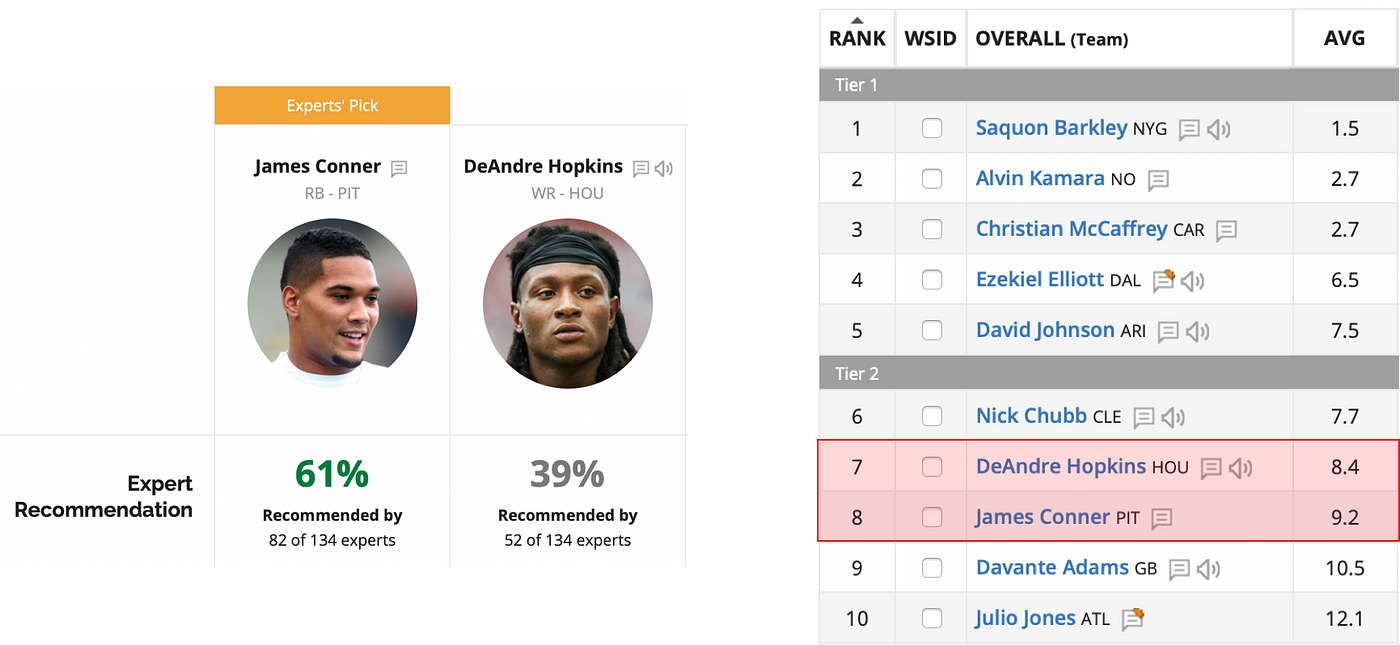
Screenshots of FantasyPros consensus draft rankings on September 2, 2019. Experts have a pairwise preference for James Conner over DeAndre Hopkins, but Hopkins is ranked higher in the consensus rankings.
There seems to be a disconnect between experts’ pairwise preferences (most prefer James Conner) and the consensus rankings on FantasyPros (DeAndre Hopkins is ranked higher). Instant runoff corrects this issue—when using instant runoff on the same data, Conner and Hopkins swap places compared to the FantasyPros consensus rankings.
Rankings and results
I scraped data from the sources that FantasyPros uses and applied a few rank aggregation methods to them. For the most part the results from all of the methods are very similar, but each one diverges slightly from the FantasyPros consensus. You can find my aggregated draft rankings for standard scoring as of September 2nd at this link.
(Note: the FantasyPros column in my rankings might not exactly match the website. FantasyPros doesn’t publish all of the raw data they use to create their consensus rankings, so my scraped data might not exactly match the data they’re aggregating.)
I don’t know which aggregation method will give the best results and I plan on evaluating them as the season goes on, so look out for a future post. I also plan on producing weekly rankings using the same approach.